전략 패턴으로 금액 정산 비즈니스 로직 성능 비교하기
들어가며
-
전략 패턴을 활용하여 간단한 엔티티 조회 및 생성 과정에서의 로직 성능을 비교해봅니다.
-
티끌(Tikkle)은 ‘시간’이라는 내부 재화를 통해 단체 내 구성원 간 서로 도움을 쉽게 주고받기 위해 만든 플랫폼 웹사이트입니다. 구성원은 도움을 주고 받으며 ‘시간’을 소비하고 획득하며, 나아가 환전 기능을 통해 ‘시간’을 랭킹 포인트로 바꿀 수 있습니다. 정산 기능은 이러한 활동의 무결성을 검증하고, 이상 거래를 감지하는 밑바탕이 되는 중요한 기능입니다.
-
계좌 정산 작업의 밑바탕이 되는, Account 엔티티의 마지막 상태를 저장하는 BalanceSnapshot 엔티티 생성 방식 비교에 따른 성능 차이를 비교합니다.
-
자세한 내용은 아래 링크에서 확인하실 수 있습니다.
-
최종 수정일: 2025-03-08
전략 패턴 선정
서비스 고려사항
저희 프로젝트 서비스 티끌(Tikkle)에서는 매일 00:00에 다음날의 계좌 정산 작업을 위한 스냅샷을 생성하는 작업이 있습니다. 정산 관련 모든 프로세스는 23:30 ~ 익일 00:30, 서비스 중단 시간에 이루어지기로 기획했습니다.
그러므로 정산 프로세스의 시간을 줄인다면 서버 다운타임을 최대한 줄일 수 있을 것이라 생각합니다. 나아가 플랫폼에서 활용하는 재화와 관련된 거래 활동을 제외하면 추후 서버를 내리지 않는 방식을 채택할 수도 있겠습니다. 따라서 존재하는 모든 계좌에 대한 정산 작업 및 그 사전 작업에 대해서 최대한 비용을 줄이는 선택지를 찾고자 합니다.
기술적 고려사항
부족하게나마 테스트 코드를 짜면서, 여러 메서드의 성능을 비교하려 서비스 컴포넌트에서 메서드를 여러 개 작성했던 경험이 있는데요. 제가 기존에 느꼈던 문제점은 다음과 같습니다.
-
개방 폐쇄 원칙 위반
개방 폐쇄 원칙(Open Closed Principle)은 클래스에 대해서 확장에는 열려있어야 하고, 수정에는 닫혀있어야 한다는 원칙입니다. 즉, 기존 코드를 변경하지 않고 기능을 추가할 수 있어야 하는데요. 하지만 서비스 클래스에 여러 메서드를 작성하게 된다면 기존 코드를 변경하는 것이 불가피해집니다. 새로운 방식을 이용하는 코드를 추가할 때마다 서비스 클래스를 직접 수정해야 하니까요.
-
단일 책임 원칙 위반
Spring에서 서비스 클래스는 비즈니스 로직을 담당해야 하는데, 성능 테스트를 위해서 서비스에 여러 메서드를 작성하는 것이 객체 지향에서의 SRP(Single Responsibility Principle) 원칙을 위배하는 게 아닐까, 하는 의문이 들었습니다. 특히, 비교를 위해 여러 메서드에서 사용되는 모든 Repository에 의존하며 결합도를 높인다는 점도 문제라고 생각했습니다.
그렇다면, SRP를 지키면서 서비스 클래스에 application 프로필 설정 혹은 @Qualifier 어노테이션을 이용해 의존성을 주입함으로써 테스트를 진행하면 되지 않을까요?
-
애플리케이션 재시작 오버헤드
그러나 오직 하나의 빈 주입을 이용한다면, 컴파일 시 정적으로 결정된 단일 전략만 사용이 가능합니다. 따라서 런타임 시 전략을 자유롭게 적용하기 위해서는 서로 다른 빈을 주입하기 위해, 테스트 코드 시 애플리케이션을 재시작하므로 불편을 낳습니다. 테스트 데이터를 준비하는 과정에서도 마찬가지입니다.
따라서 단일 책임 원칙을 준수함은 물론, 런타임에서 전략을 자유롭게 적용할 수 있는 방법이 필요했습니다. 바로 전략 패턴을 도입하는 일이었습니다.
전략 패턴에 대해서
전략 패턴의 정의
전략 패턴은 런타임에 유연하게 알고리즘을 택할 수 있도록, 알고리즘의 집합을 정의하고 서로 교체할 수 있도록 하는 디자인 패턴인데요.
전략 패턴은 세 가지 요소로 이루어집니다. 전략 인터페이스(Strategy Interface), 구체적인 전략(Concrete Strategies), 컨텍스트(Context)입니다.
- 전략 인터페이스
전략 인터페이스는 구체적인 전략이 따라야 할 행동 계약을 정해놓은 공통 인터페이스입니다.
- 구체적인 전략
구체적인 전략은 인터페이스의 계약을 준수하는 실제 알고리즘으로, 전략 인터페이스를 구현하는 클래스입니다. 각 전략은 특정 알고리즘에 대한 책임만 가집니다.
- 컨텍스트
컨텍스트는 전략 객체를 사용하는 역할을 하는 클래스입니다. 컨텍스트는 전략 인터페이스를 사용하여 알고리즘을 선택하고 실행합니다. 컨텍스트는 알고리즘과 관련된 전략을 이용하는 책임만 가집니다.
전략 패턴을 적용하기 전에
- 알고리즘 캡슐화
전략 패턴은 각 알고리즘을 구체적인 전략 클래스로 캡슐화합니다. 컨텍스트는 전략 객체를 이용하지만, 알고리즘의 세부 구현에 대해서 알지 못합니다. 따라서 알고리즘의 내부 로직이 변경되어도 컨텍스트의 코드는 변경되지 않습니다.
- 인터페이스 기반 의존성 역전
모든 전략 클래스은 공통 인터페이스를 구현하고, 컨텍스트는 이 인터페이스를 사용하여 전략을 전달받습니다. 따라서 컨텍스트는 전략 클래스의 구체적인 구현에 의존하지 않습니다.
- 상속보다는 구성
전략 패턴은 상속보다는 컴포지션을 이용해 객체의 행위를 변경합니다. 컴포지션은 다른 클래스의 인스턴스를 포함하고(HAS-A), 인스턴스는 실행 중에 교체될 수 있으며, 인터페이스를 통해 느슨하게 결합되어 있습니다. 반면, 상속은 IS-A 관계를 따르고, 그 관계는 컴파일 타임에 결정되며, 하위 클래스가 상위 클래스에 강하게 의존합니다.
계좌 스냅샷 생성 전략 패턴
객체 중심적인 개발을 시도하며 사용했던 JPA는 객체 지향적으로 데이터를 다룰 수 있지만, 정산 로직을 작성하면서는 과연 최선의 선택이 맞는지 의문이 들었습니다. 특히, 정산 로직과 계좌 스냅샷은 엔티티 조회 및 생성이라는 흐름이 비슷하므로, 계좌 스냅샷에서 더 적절한 대안은 정산 로직 자체에서도 적용할 수 있다고도 가정했습니다.
현재의 정산 로직
시간과 랭킹 포인트를 소지하고 있는 Account 엔티티는 Member와 일 대 일 관계로 매핑되어 있습니다. 저희의 목표는 매일 존재하는 모든 계좌의 시간 및 랭킹 포인트 재화 상태가 재화에 대한 거래 내역과 환전 내역에 일치하는 상태인지 확인하는 것이었는데요. 정산 로직은 아래와 같습니다.
-
도움을 주고 받으며 Account에 직접 시간 재화량에 대한 변경, 환전을 통해 랭킹 포인트 재화량에 대한 변경이 발생
-
해당 변경 발생 시 로그 테이블에 거래 내역과 환전 내역을 남김
-
이전일 정산 작업 이후 생성된 BalanceSnapshot 엔티티에 기반한 검증 작업
- 당일 가입한 Member의 Account는 가입 시 초기 설정값에 대한 스냅샷
- 비교: 전일 BalanceSnapshot 엔티티 기록 + 당일 거래 및 환전 로그 기록값 == 당일 Account 재화량
-
이후 이상 거래 혹은 이상 계좌 감지
그러나 서비스 고려사항과 기술적 고려사항을 떠올리며, 과연 JPA를 사용하는 게 맞는지 확신이 들지 않았습니다. 오히려 자료를 조사하면서, JDBC를 직접 이용하는 편이 훨씬 나을 것 같았습니다.
JPA가 비효율적이라면 왜 비효율적인지, JDBC가 효율적이라면 얼마나 효율적인지 명확한 근거가 필요하다고 생각했습니다. 따라서 테스트에서 런타임에 유연하게 전략을 변경해 어플리케이션 재시작을 줄이고 알고리즘 작성 시의 유연성도 높이는 전략 패턴을 적용해보고자 했습니다.
전략 패턴 도식
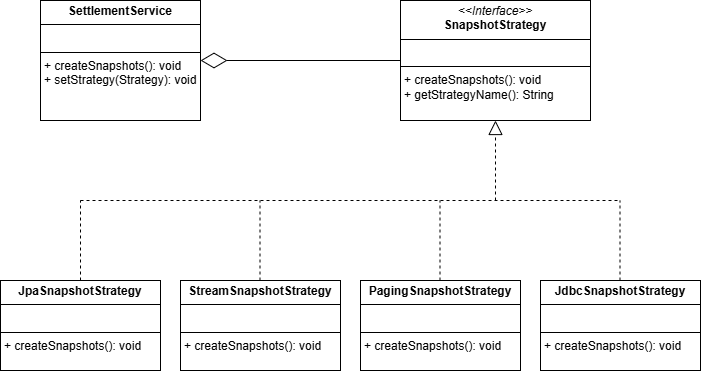
앞서 설명한 정의에서와 같이 전략 패턴의 요소는 다음과 같이 작성했습니다.
- 컨텍스트:
SettlementService - 전략 인터페이스:
SnapshotStrategy - 구체적인 전략:
JpaSnapshotStrategy,StreamSnapshotStrategy,PagingSnapshotStrategy,JdbcSnapshotStrategy
SettlementService는 SnapshotStrategy 타입의 필드 인스턴스를 가지는데요. 위 인터페이스를 구현한 구체적인 전략의 createSnapshot() 메서드 내용은 알지 못하도록 캡슐화 되어 있습니다.
그런데 분명히, 앞서 상속보다는 컴포지션을 이용한다는 설명과 달리 UML에서는 어그리게이션으로 표현했습니다.
이는 전략 패턴이 일반적으로 컴포지션을 사용하지만 Spring 환경에서는 집합 관계에 가깝다는 점을 표현하고 싶었습니다.
Spring 환경 상 구체적인 전략이 Spring 컨테이너에 등록되어 관리되기에, SettlementService와 SnapshotStrategy 인터페이스 구현체 Bean은 서로 독립적입니다.
Spring 컨테이너가 각 Bean의 생성과 소멸을 독립적으로 관리하므로, 컨텍스트가 소멸해도 전략 객체는 계속 존재할 수 있습니다.
즉, 컴포지션이 강한 HAS-A 관계로 생명 주기를 공유하는 반면, Spring 환경 상 이번에 구현된 전략 패턴은 생명 주기가 독립적이므로 어그리게이션으로 표현했습니다.
전략 패턴 적용
엔티티
Account.java
@Entity
@Table(name = "accounts")
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class Account extends AuditableEntity {
@Id
@Column(columnDefinition = "BINARY(16)")
private UUID id = UlidCreator.getMonotonicUlid().toUuid();
@OneToOne(fetch = FetchType.LAZY)
@JoinColumn(name = "member_id", nullable = false)
private Member member;
@Column(name = "time_qnt", columnDefinition = "INTEGER")
private Integer timeQnt;
@Column(name = "ranking_point", columnDefinition = "INTEGER")
private Integer rankingPoint;
// ...
}
BalanceSnapshot.java
@Entity
@Table(name = "balance_snapshot")
@Getter
@NoArgsConstructor(access = AccessLevel.PROTECTED)
public class BalanceSnapshot extends BaseEntity {
@Id
@Column(columnDefinition = "BINARY(16)")
private UUID id = UlidCreator.getMonotonicUlid().toUuid();
// 계좌 ID 이외의 정보는 필요하지 않으므로 Id만 이용
@Column(nullable = false)
private UUID accountId;
@Column(nullable = false)
private int timeQnt;
@Column(nullable = false)
private int rankingPoint;
@Builder
private BalanceSnapshot(UUID accountId, int timeQnt, int rankingPoint) {
this.accountId = accountId;
this.timeQnt = timeQnt;
this.rankingPoint = rankingPoint;
}
}
BalanceSnapshot.java에서는 스냅샷 조회 시 불필요한 Account 엔티티 조인이 발생하지 않도록 계좌 ID만 저장합니다. 이는 스냅샷이 특정 시점의 데이터 상태를 그대로 보존하는 것이 목적이므로, Account 엔티티 변경 사항에 영향을 받지 않으므로 따로 엔티티 매핑을 지정해주지 않았습니다.
컨텍스트
SettlementService.java
@Service
@RequiredArgsConstructor
public class SettlementService {
// ... 관련된 코드만 표시
private SnapshotStrategyType snapshotStrategyType;
private SnapshotStrategy snapshotStrategy;
@Transactional
@Scheduled(cron = "0 0 0 * * *")
public void createSnapshots() {
logger.info("Creating snapshots with strategy: {} ({})",
snapshotStrategyType.name(), snapshotStrategyType.getDescription());
long startTime = System.nanoTime();
snapshotStrategy.createSnapShots();
long endTime = System.nanoTime();
logger.info("Completed snapshot creation in {} ms", TimeUnit.NANOSECONDS.toMillis(endTime - startTime));
}
}
컨텍스트인 SettlementService는 전략 인터페이스인 SnapshotStrategy를 필드로 가지고 있습니다. SnapshotStrategyType은 기록을 측정하고 관리하기 위한 Enum 클래스입니다.
전략 인터페이스
SnapshotStrategy.java
public interface SnapshotStrategy {
void createSnapShots();
String getStrategyName();
}
전략 인터페이스인 SnapshotStrategy는 전략 패턴의 핵심 요소입니다. 이 인터페이스는 모든 구체적인 전략이 구현해야 하는 메서드를 정의합니다.
구체적인 전략
스냅샷 생성 전략을 고민한 과정에서의 간단한 정리는 이 링크를 참고해주세요.
JpaSnapshotStrategy.java
@Component("jpaSnapshotStrategy")
@RequiredArgsConstructor
public class JpaSnapshotStrategy implements SnapshotStrategy {
private final AccountRepository accountRepository;
private final BalanceSnapshotRepository balanceSnapshotRepository;
private static final Logger logger = LoggerFactory.getLogger(JpaSnapshotStrategy.class);
@Override
// 작성: 기본적인 findAll(), saveAll() 메서드를 이용한 전략
public void createSnapShots() {
List<Account> accounts = accountRepository.findAll();
List<BalanceSnapshot> snapshots = accounts.stream()
.map(account -> BalanceSnapshot.builder()
.accountId(account.getId())
.timeQnt(account.getTimeQnt())
.rankingPoint(account.getRankingPoint())
.build())
.toList();
balanceSnapshotRepository.saveAll(snapshots);
}
@Override
public String getStrategyName() {
return SnapshotStrategyType.JPA.getDescription();
}
}
가장 처음 기능을 작성하며, 로직의 흐름을 나타내기 위해 빠르게 작성한 코드입니다. 기본적으로 BalanceSnapshot 엔티티, Account 엔티티와 각각 매핑된 JpaRepository의 findAll()과 saveAll() 메서드를 이용합니다.
당연하게도, 이 코드는 문제 의식의 출발점이 된 코드입니다. 메모리 부족 등의 이유로 데이터를 모두 로드하는 것이 불가능하거나 비용적으로 비효율적임을 걱정했습니다.
StreamSnapshotStrategy.java
@Component("streamSnapshotStrategy")
@RequiredArgsConstructor
public class StreamSnapshotStrategy implements SnapshotStrategy {
private final AccountCustomRepository accountCustomRepository;
private final BalanceSnapshotRepository balanceSnapshotRepository;
@PersistenceContext
private EntityManager entityManager;
private static final Logger logger = LoggerFactory.getLogger(StreamSnapshotStrategy.class);
@Override
public void createSnapShots() {
logger.info("Creating snapshots using Stream API strategy");
int fetchSize = 1000;
int processedCount = 0;
try (Stream<Account> accountStream = accountCustomRepository.findAllWithStream(fetchSize)) {
List<BalanceSnapshot> batchSnapshots = new ArrayList<>(fetchSize);
Iterator<Account> iterator = accountStream.iterator();
while (iterator.hasNext()) {
Account account = iterator.next();
BalanceSnapshot snapshot = convertToSnapshot(account);
batchSnapshots.add(snapshot);
if (batchSnapshots.size() >= fetchSize) {
processedCount += batchSnapshots.size();
balanceSnapshotRepository.saveAll(batchSnapshots);
entityManager.flush();
entityManager.clear();
batchSnapshots.clear();
}
}
if (!batchSnapshots.isEmpty()) {
processedCount += batchSnapshots.size();
balanceSnapshotRepository.saveAll(batchSnapshots);
entityManager.flush();
entityManager.clear();
}
}
logger.info("Created {} snapshots using Stream API strategy", processedCount);
}
@Override
public String getStrategyName() {
return SnapshotStrategyType.STREAM.getDescription();
}
// ...
}
StreamSnapshotStrategy는 JPA Stream API는 설정된 fetch size에 따라서 일정량의 데이터를 메모리에 로드하고, 처리 후 다음 청크를 가져오는 방식입니다. saveAll() 메서드 역시 청크 내 데이터의 개수만큼만 반복적으로 처리합니다. 그러므로 이 전략에서는 Stream이 유지되는 동안 DB와의 연결이 유지되어야 합니다.
entityManager를 이용해 트랜잭션 내에서 영속성 컨텍스트에 데이터가 남아있어 메모리가 낭비되지 않도록 해야합니다. 특히 Iterator를 이용하여 배치 단위로 계좌 엔티티를 불러오고 스냅샷을 저장합니다. 따라서 트랜잭션 내에서 flush()를 통해 지속적으로 변경사항을 커밋하고, clear()를 통해 영속성 컨텍스트를 초기화하는 작업이 필요합니다.
PagingSnapshotStrategy.java
@Component("pagingSnapshotStrategy")
@RequiredArgsConstructor
public class PagingSnapshotStrategy implements SnapshotStrategy {
private final AccountRepository accountRepository;
private final BalanceSnapshotRepository balanceSnapshotRepository;
@PersistenceContext
private EntityManager entityManager;
private static final Logger logger = LoggerFactory.getLogger(PagingSnapshotStrategy.class);
@Override
@Transactional
public void createSnapShots() {
logger.info("Creating snapshots using Paging strategy");
int pageSize = 1000;
int pageNumber = 0;
int totalProcessed = 0;
boolean hasMoreData = true;
while (hasMoreData) {
// 1. COUNT 쿼리 없는 Slice로 account 가져오기
Pageable pageable = PageRequest.of(pageNumber, pageSize);
Slice<Account> accountSlice = accountRepository.findAllAsSlice(pageable);
// 2. 해당 Slice 내에서 BalanceSnapshot으로 변경
List<BalanceSnapshot> batchSnapshots = accountSlice.getContent().stream()
.map(this::convertToSnapshot)
.collect(Collectors.toList());
// 3. 영속화 이후 영속성 컨텍스트 초기화
balanceSnapshotRepository.saveAll(batchSnapshots);
entityManager.flush();
entityManager.clear();
totalProcessed += batchSnapshots.size();
logger.debug("Processed page {} with {} accounts", pageNumber, batchSnapshots.size());
// 4. 다음 Slice 준비
pageNumber++;
hasMoreData = accountSlice.hasNext();
}
logger.info("Created {} snapshots using Paging strategy", totalProcessed);
}
@Override
public String getStrategyName() {
return SnapshotStrategyType.PAGING.getDescription();
}
// convertToSnapshot() 메서드는 생략
}
PagingSnapshotStrategy는 페이징 처리를 이용합니다. 스냅샷 생성 로직에서는 따로 전체 페이지가 필요한 것이 아니므로, Page 대신 Slice를 이용해 COUNT 쿼리에 따르는 오버헤드를 줄였습니다.
@Query("SELECT a FROM Account a")
Slice<Account> findAllAsSlice(Pageable pageable);
JPA Stream과 달리, 페이징 처리를 이용하면 각 페이지는 독립적인 쿼리로 처리됩니다. 그러나 createSnapshot() 자체가 @Transactional을 통해서 하나의 트랜잭션으로 처리되므로, StreamSnapshotStrategy와 비슷하게 영속성 컨텍스트를 관리했습니다.
JdbcSnapshotStrategy.java
@Component("jdbcSnapshotStrategy")
@RequiredArgsConstructor
public class JdbcSnapshotStrategy implements SnapshotStrategy {
private final BalanceSnapshotCustomRepository balanceSnapshotCustomRepository;
private static final Logger logger = LoggerFactory.getLogger(JdbcSnapshotStrategy.class);
@Override
@Transactional
public void createSnapShots() {
logger.info("Creating snapshots using JDBC");
int insertedCount = balanceSnapshotCustomRepository.insertDirectlyFromAccounts();
logger.info("Created {} snapshots using JDBC directly SELECT INTO", insertedCount);
}
@Override
public String getStrategyName() {
return SnapshotStrategyType.JDBC.getDescription();
}
// ...
}
JdbcSnapshotStrategy.java는 Spring 6.1부터 이용 가능한 JDBC Client를 이용하여 직접 데이터에 접근하는 방식입니다. 위에서 이용하는 balanceSnapshotCustomRepository.insertDirectlyFromAccounts() 메서드는 아래와 같습니다.
@Override
public int insertDirectlyFromAccounts() {
logger.info("Starting INSERT INTO SELECT of balance snapshots directly from account table");
// INSERT INTO SELECT 문으로 애플리케이션 메모리 사용 없이 DB 내부에서 직접 데이터 변환 및 삽입
int rowsAffected = jdbcClient.sql(
"INSERT INTO balance_snapshot (id, account_id, time_qnt, ranking_point, created_at) " +
"SELECT " +
" CONCAT(UNHEX(LPAD(HEX(ROUND(UNIX_TIMESTAMP(NOW(3)) * 1000)), 12, '0')), " +
" UNHEX(LEFT(MD5(CONCAT(UUID(), RAND())), 20))), " + // 랜덤 부분 (80비트 = 10바이트)
" id, time_qnt, ranking_point, NOW() " +
"FROM accounts")
.update();
logger.info("INSERT INTO SELECT completed, inserted {} records", rowsAffected);
return rowsAffected;
}
가장 중요한 점은 BalanceSnapshot 엔티티가 필요로 하는 필드는 Account 엔티티에 모두 존재하므로, 위와 같이 직접 데이터를 변환해 삽입할 수 있다는 점입니다.
따라서 처음에는 JdbcTemplate에서 지원하는 Bulk Insert를 고려해보았으나, 데이터에 대한 추가적인 변환이나 작업이 필요없다는 점에 착안해 직접 INSERT INTO SELECT 문을 이용했습니다.
ID로 이용하고 있는 ULID를 기존 어플리케이션 단에서 생성한 것과 달리, 위는 MariaDB 내부에서 직접 생성해야하므로 id에 대해 ULID를 BINARY(16)으로 저장하도록 했습니다.
이 방법에서는 데이터가 애플리케이션 메모리로 로드되는 대신 DB 엔진 내에서 작업이 수행되며, 트랜잭션 오버헤드도 최소화 될 것으로 기대했습니다.
계좌 스냅샷 생성 테스트
테스트 환경 및 설정
계좌 스냅샷 생성 전략들의 성능을 비교하기 위한 테스트 환경은 다음과 같이 구성되었습니다:
데이터베이스
TestContainers를 사용한 MariaDB 10.6 컨테이너
- 데이터베이스명:
snapshot_test - UTF-8 문자셋, 256MB InnoDB 버퍼 풀 크기
- JDBC 설정:
rewriteBatchedStatements=true로 배치 처리 최적화 - 인메모리 데이터베이스 대신, 운영 환경과 유사하게 Docker 이미지를 이용하기 위해 TestContainers를 이용했습니다. (자세한 사항은 다음 글에서 다뤄보겠습니다.)
JPA 설정
- Hibernate 배치 크기: 100 (5000, 1000, 100 테스트 후 100 선택)
- 배치 삽입/업데이트 최적화
- 통계 및 SQL 로깅
테스트 데이터
- 총 50,000개의 BalanceSnapshot 데이터 생성
- 각 계좌는 회원 정보와 연결되며, 범위 내 무작위 시간 재화량(timeQnt)과 랭킹 포인트(rankingPoint) 양을 포함
- Account와 Member는 JDBC 배치 처리를 통해 생성되며, 런타임 내에서 데이터베이스에 저장되며 재사용됨.
테스트 방식
스냅샷 생성에 관한 각 전략은 다음 지표를 기준으로 평가됩니다. JMH와 같은 벤치마킹 툴을 이용하는 것이 바람직하나, 현재는 기능 개발에 우선 순위를 두므로 이용하지 않았습니다.
- 실행 시간: 전략 실행에 소요된 시간(밀리초)
- 메모리 사용량: 전략 실행 중 사용된 메모리(MB)
- 생성된 스냅샷 수: 각 전략이 생성한 스냅샷의 총 개수
테스트를 작성하며
@DataJpaTest
@DataJpaTest 어노테이션을 통해, JPA 설정을 구성하고 전체적인 코드 대신 성능 비교에서 중점을 두는 Repository 계층 중심으로 빠르게 테스트를 작성했습니다. 전략 패턴과 관계되어 추가적으로 필요한 컴포넌트는 @Import 어노테이션을 통해 주입했습니다.
특히, @DataJpaTest는 롤백 기능을 기본값으로 지원하므로 테스트 메서드가 종료되면 트랜잭션이 롤백됩니다. 따라서 테스트 메서드가 종료되면 트랜잭션이 롤백됩니다.
@Transactional
중요한 것은 SettlementService에서의 트랜잭션이지, 테스트 메서드의 트랜잭션이 메인은 아닙니다. 게다가 @DataJpaTest가 각 테스트 메서드를 감싸 롤백을 진행한다면, BalanceSnapshot 엔티티를 생성하기 위해 미리 생성해 둔 Account와 Member 엔티티 데이터를 중복해서 작성해야 합니다.
따라서 테스트 메서드에서는 @Transactional(propagation = Propagation.NOT_SUPPORTED) 어노테이션을 통해 트랜잭션을 비활성화하고, 테스트 메서드가 종료되면 롤백을 진행하지 않도록 했습니다. 덕분에 BalanceSnapshot을 생성하기 위해 동일한 데이터를 재사용할 수 있었습니다.
그리고 NOT_SUPPORTED 설정은 테스트 메서드 자체가 트랜잭션 없이 실행되도록 지정해, 비즈니스 로직 내에서의 트랜잭션 경계를 유지할 수 있도록 했습니다.
각 테스트 메서드 마다 생성된 BalanceSnapshot 엔티티는 BalanceSnapshotRepository.deleteAllInBatch()를 이용해 매 테스트마다 수동으로 제거했습니다. 최종적으로 생성된 데이터에 대해서, TestContainers를 이용해 생성된 MariaDB 컨테이너는 테스트 메서드가 종료되면 자동으로 소멸됨을 참고했습니다.
@AutoConfigureTestDatabase
TestContainers를 이용하는 목표 중 하나가, 운영 시 이용하는 MariaDB Docker 이미지 환경에 있으므로 @AutoConfigureTestDatabase(replace = AutoConfigureTestDatabase.Replace.NONE) 어노테이션을 통해 인메모리 데이터베이스를 이용하지 않게 했습니다.
@DynamicPropertySource
@DynamicPropertySource
static void registerMariaDBProperties(DynamicPropertyRegistry registry) {
registry.add("spring.datasource.url", () -> mariaDBContainer.getJdbcUrl() + "?rewriteBatchedStatements=true");
registry.add("spring.datasource.username", mariaDBContainer::getUsername);
registry.add("spring.datasource.password", mariaDBContainer::getPassword);
registry.add("spring.datasource.driver-class-name", mariaDBContainer::getDriverClassName);
// JPA 설정 추가
registry.add("spring.jpa.hibernate.ddl-auto", () -> "create");
registry.add("spring.jpa.show-sql", () -> "false");
registry.add("spring.jpa.properties.hibernate.format_sql", () -> "true");
registry.add("spring.jpa.properties.hibernate.generate_statistics", () -> "true");
registry.add("logging.level.org.hibernate.SQL", () -> "DEBUG");
registry.add("logging.level.org.hibernate.type.descriptor.sql.BasicBinder", () -> "TRACE");
registry.add("logging.level.org.hibernate.jdbc.batch", () -> "TRACE");
registry.add("spring.jpa.properties.hibernate.jdbc.batch_size", () -> "100");
registry.add("spring.jpa.properties.hibernate.order_inserts", () -> "true");
registry.add("spring.jpa.properties.hibernate.order_updates", () -> "true");
registry.add("spring.jpa.properties.hibernate.jdbc.batch_versioned_data", () -> "true");
}
@DynamicPropertySource는 테스트 실행 시 동적으로 Spring 환경의 프로퍼티 값을 설정할 수 있게 해주는데요. 이를 이용해 각 테스트 클래스마다 독립적인 리소스를 구성할 수 있으며, 이번 성능 비교에서는 TestContainers를 이용해 생성한 MariaDB 컨테이너의 연결 정보를 설정할 수 있는 데 이용했습니다. 이는 꼭 static 메서드에서만 사용가능합니다.
전략 패턴과 테스트
private void testStrategy(SnapshotStrategy strategy, SnapshotStrategyType strategyType) {
// 메모리 및 시간 측정
long startMemory = Runtime.getRuntime().totalMemory() - Runtime.getRuntime().freeMemory();
long startTime = System.nanoTime();
// 전략 실행
settlementService.setSnapshotStrategy(strategyType, strategy);
settlementService.createSnapshots();
// 결과 계산 및 검증
// ...
}
모든 전략에 대해 동일한 테스트 로직을 이용해, 테스트 코드를 간결하고 일관성 있게 유지할 수 있었습니다. 알고리즘에 대해 각기 다른 클래스를 만들었다면 중복된 코드가 발생했을 것이고, 상속이 사용된다면 런타임에 유연하게 이용하지 못했을 것입니다.
// Bean으로 올라간 snapshotStrategy에 대한 Map 주입
@Autowired
private Map<String, SnapshotStrategy> snapshotStrategyMap;
@Test
@Transactional(propagation = Propagation.NOT_SUPPORTED)
@Order(1)
public void testJpaStrategy() {
logger.info("Testing JPA strategy...");
SnapshotStrategy strategy = snapshotStrategyMap.get(SnapshotStrategyType.JPA.getBeanName());
testStrategy(strategy, SnapshotStrategyType.JPA);
}
또한, 만약 전략 패턴을 이용하지 않고 각 알고리즘을 클래스로 구현해 이용했다면 단순히 알고리즘 간 성능은 비교할 수 있겠지만, 실제 비즈니스 로직이 무의미해졌을 것이라고 생각합니다. 현재 SettlementService는 로깅을 진행하고, 트랜잭션 경계를 설정하는 역할을 수행합니다. 알고리즘 별 클래스를 따로 만들었다면 이는 무시되었을 것입니다.
테스트 결과
Strategy: JPA findAll() saveAll() with Batch, Execution time: 91194 ms, Memory used: 100 MB, Snapshots created: 50000
Strategy: STREAM API with Batch, Execution time: 65464 ms, Memory used: -35 MB, Snapshots created: 50000
Strategy: PAGING with Batch, Execution time: 67203 ms, Memory used: -61 MB, Snapshots created: 50000
Strategy: JDBC SELECT INTO, Execution time: 1076 ms, Memory used: 0 MB, Snapshots created: 50000
위는 System.nanoTime()로 시간을 측정하고, Runtime.getRuntime().totalMemory()와 Runtime.getRuntime().freeMemory()를 이용해 메모리 사용량을 측정한 결과입니다.
분명히 Execution Time과 달리, Memory used에서 음수가 나오는데요. 이는 메모리 사용량에 대해 신뢰할 수 없는 측정 방식임을 알 수 있습니다.
추측하건대, Garbage Collector가 작동하면서 메모리 사용량의 변화가 생겼거나 처리 중간에의 메모리 사용량을 반영하지 못할 가능성이 높습니다.
따라서 IntelliJ에서 제공하는 프로파일러를 통해서 CPU 타임과 메모리 할당량 역시 측정해보았습니다. CPU 타임에는 순수 Java 코드 실행 시간과 JVM 내부 작업 시간이 포함되고, I/O 대기시간이나 쿼리 실행 대기 시간 등은 포함되지 않습니다.
실행 시간 System.nanoTime()
| 전략 | 실행 시간 | 상대적 성능 |
|---|---|---|
| JPA | 91,194 ms | 1.0x (기준) |
| Stream | 65,464 ms | 1.4x 빠름 |
| Paging | 67,203 ms | 1.4x 빠름 |
| JDBC | 1,076 ms | 84.8x 빠름 |
CPU 타임 (IntelliJ 프로파일러)
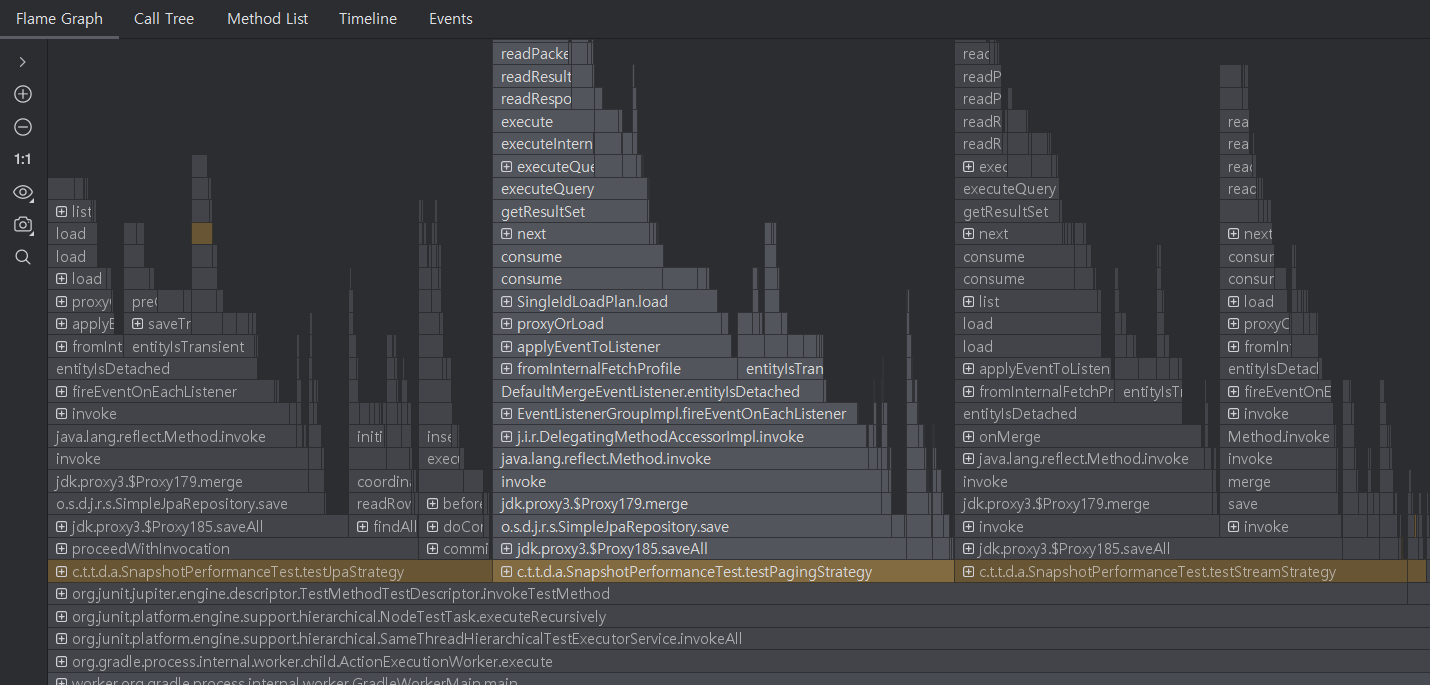
| 전략 | CPU 타임 | 상대적 성능 |
|---|---|---|
| JPA | 5,795 ms | 1.0x (기준) |
| Stream | 3,883 ms | 1.5x 빠름 |
| Paging | 3,970 ms | 1.5x 빠름 |
| JDBC | 프로파일러에 나타나지 않음 | - |
메모리 할당량 (IntelliJ 프로파일러)
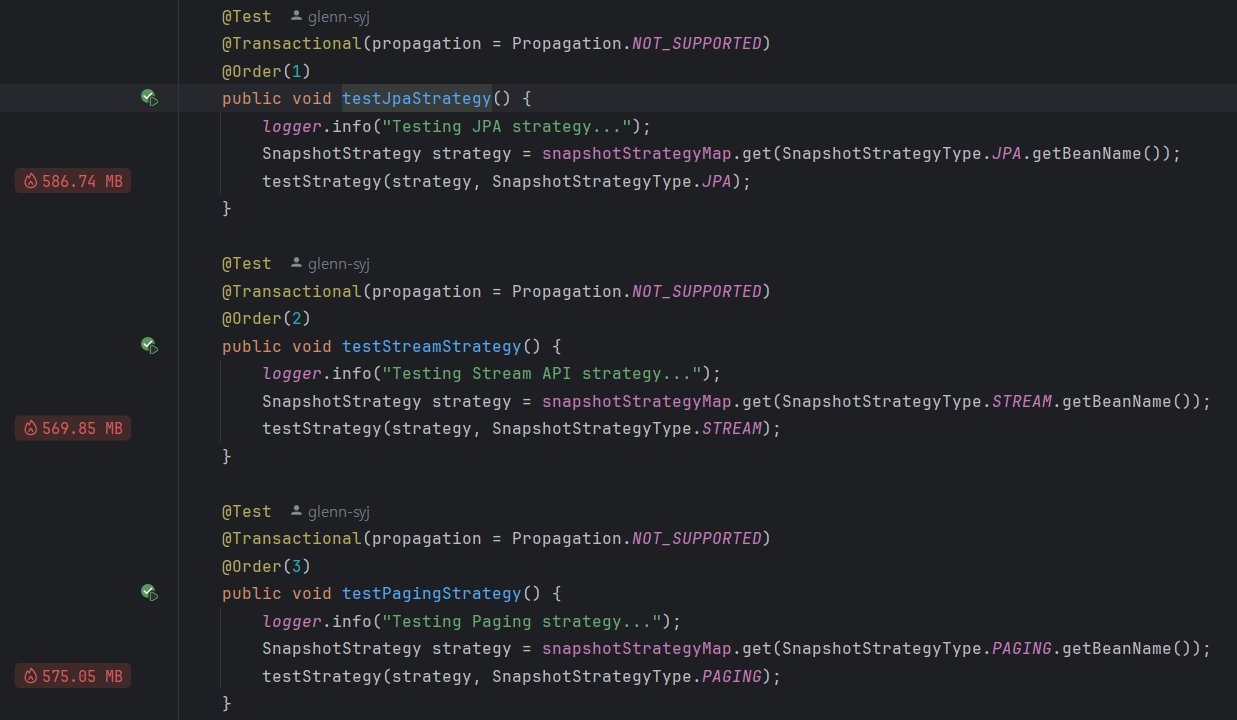
| 전략 | 메모리 할당량 | 상대적 효율성 |
|---|---|---|
| JPA | 586.74 MB | 1.0x (기준) |
| Stream | 569.85 MB | 1.03x 효율적 |
| Paging | 575.05 MB | 1.02x 효율적 |
| JDBC | 프로파일러에 나타나지 않음 | - |
JDBC 전략의 메모리 할당량이 측정되지 않은 이유는 이 전략이 Java 애플리케이션에서 거의 객체를 생성하지 않고, 대부분의 작업을 데이터베이스 엔진 내에서 직접 수행하기 때문입니다.
실제로는 데이터베이스 서버에서 메모리를 사용하지만, 이는 Java 프로파일러로 측정할 수 없기 때문임 역시 참고해주시면 좋겠습니다. 이후 스냅샷 생성의 기본 전략은 테스트 결과에 기반해 JDBC 전략을 이용하기로 결정했습니다.
나가며
이번 글에서는 대량의 계좌 스냅샷 생성 작업에서 다양한 데이터 처리 전략의 성능을 비교해보았습니다. 전략 패턴을 활용하여 JPA, Stream API, Paging, JDBC 기반의 네 가지 전략을 구현하고 각각의 성능을 측정한 결과, JDBC 전략이 다른 전략들에 비해 압도적인 성능 우위를 보였습니다. 물론 JPQL, Native Query 등의 방식을 이용하면 JPA 역시 비교적 효율적으로 작업을 진행할 수 있겠지만 이번에는 서비스 중단 시간과 대량 데이터 상황을 고려하여 JDBC Client를 선택했습니다.
성능 측정 과정에서 실행 시간(Wall-clock Time)과 CPU 타임의 차이를 확인할 수 있었습니다. 특히 JPA 전략의 경우 실행 시간(91,194ms)과 CPU 타임(5,795ms) 사이에 큰 차이가 있었는데, 이는 데이터베이스 I/O 대기 시간, 트랜잭션 오버헤드, 영속성 컨텍스트 관리 등이 실행 시간에는 포함되지만 CPU 타임에는 포함되지 않기 때문입니다.
또한, 전략 패턴을 통해 코드를 유연하게 확장하고 재사용하면서 객체 지향 프로그래밍이 가지는 장점을 확인할 수 있었습니다. 단일 책임 원칙, 의존성 역전 원칙, 개방-폐쇄 원칙 등의 객체 지향 프로그래밍 원칙이 단순히 이론이 아니라 정말로 의미가 있다는 것을 배웠습니다. 성능을 비교하면서, 오히려 재사용이 가능하고 결합도가 낮은 코드에 대해서도 고민해야 한다는 것을 배웠습니다.
전략 패턴의 UML 역시 그려보며 얻은 경험도 있습니다. 지식으로 알고 있던 상속, 컴포지션, 어그리게이션 개념의 차이를 다시 한 번 생각해볼 수 있었습니다. 특히, 전략 패턴이 일반적으로 상속 대신 컴포지션을 활용하더라도 Spring 환경의 특성 상 생명주기에 따라 어그리게이션에 가깝다는 것을 도출해내는 과정이 기억에 남습니다.
앞으로의 스냅샷 생성 이후 정산 로직 개발에서는 이번 성능 테스트 결과를 바탕으로 JDBC 전략을 기본으로 사용하되, 비즈니스 요구사항의 변화에 따라 유연하게 전환할 수 있는 구조를 고려해 볼 계획입니다.
TestContainers를 활용한 테스트 환경 구성과 소개는 다른 글에서 더 자세히 다뤄보도록 하겠습니다.
References
- https://en.wikipedia.org/wiki/Strategy_pattern
- https://www.baeldung.com/spring-order
- https://www.geekyhacker.com/high-performance-data-fetching-using-spring-data-jpa-stream/
- https://spring.io/guides/gs/relational-data-access
- https://docs.spring.io/spring-framework/reference/data-access/jdbc/core.html#jdbc-NamedParameterJdbcTemplate