OOP 세계에서 AOP 이해하기 (1) - OOP 세계
들어가며
- Spring Transaction에서
@Transactional의 동작을 파악하며, AOP 프록시 객체를 이용한다는 것을 알게 되었습니다. - 부트캠프에서 Spring 프레임워크를 학습하며 AOP에 대해 처음 배울 당시, 공식문서에서의 보완적이라는 설명과 달리 OOP와 AOP가 서로 상반되는 패러다임이 아닌가? 하는 의문이 들었습니다.
- 이번 글에서는 OOP 세계에서 Spring AOP를 이해하기 전에, OOP 세계란 과연 어떤 세계인지 먼저 깊이 살펴봅니다.
OOP 세계
OOP를 바라보는 흔한 시선
우리는 객체 지향 프로그래밍(Object Oriented Programming)을 어떻게 이해해야 할까요? 저는 단순히 OOP를 그 특성으로만 이해하고 싶지는 않습니다.
특히 OOP에 있어 객체를 중심으로 한 세계의 모델링이라는 설명, 속성으로서의 데이터와 행위로서의 메서드라는 설명, 캡슐화-상속-다형성이라는 세 축을 중심으로 한 설명은 언뜻 말이 되지만 부족한 듯 보였습니다.
이는 모두 객체 지향 프로그래밍의 특성을 설명하는 것이지, 객체 지향 프로그래밍의 특성을 핵심적으로 관통하는 원리에는 닿지 않는다고 느끼기 때문입니다.
특히, 객체 지향 프로그래밍 역시 다른 패러다임과 마찬가지로 하늘에서 갑자기 뚝 떨어진 것은 아닐 것이며, 절차형 패러다임 속에서도 객체 지향 프로그래밍의 씨앗은 존재했을 것이기 때문입니다.
이러한 오해는 모두 객체(Object)라는 말이 주는 느낌에 과하게 집중할 때 발생합니다.
객체 혹은 행위자
객체 지향 프로그래밍을 바라보는 흔한 시선에서 객체는 수동적인 존재로 남습니다. 여기에서 수동적이라고 함은, 객체가 가지는 능동성과 객체 간 네트워크보다는 객체를 구성하는 방식과 객체 자체를 중심으로 객체가 이해된다는 의미입니다.
객체가 세계의 모델링이라는 모방론적 설명은 객체를 현실 세계에 지나치게 일 대 일 대응 시키고 있으며, 데이터와 메서드로 객체 지향 프로그래밍을 바라보는 설명은 객체를 지나치게 단순한 컨테이너 같은 존재로 보이게 합니다. 또한, 캡슐화-상속-다형성을 중심으로 한 설명은 세 특징이 곧 객체 지향 프로그래밍의 필요 충분 조건으로 여겨지게 하는 위험이 있습니다.
이러한 시선에서는 부분적으로 객체(Object)라는 용어가 내포하는 수동성이 영향을 미쳤을 수도 있다는 생각이 듭니다. 그리고 마찬가지로, 프로그래머가 능동적으로 시스템과 코드를 구성한다는 관점에서 객체 지향 프로그래밍을 이해하게 되면서 구현이 중심이 되며 객체의 수동성이 부각되었을 수 있겠습니다.
 2019년 Alan Kay의 OOP 관련 논의 (출처: hackernews)
2019년 Alan Kay의 OOP 관련 논의 (출처: hackernews)
그렇다면 앨런 케이(Alan Kay)가 훗날 객체 대신 행위자(Actor)라고 부르는 게 나았다는 후회를 한 것이 이해됩니다. 저는 앨런 케이가 진정 강조하고 싶었던 것은 원칙에 맞게 코드로 빚어낸 객체 하나하나가 아니라, 행위자로서 소통하고 대응하는 객체의 네트워크이자 그 행위 방식이라고 생각합니다.
즉, 앨런 케이의 OOP에 대한 이해는 객체가 존재하는 방식이나 형태가 아니라, 객체가 행위하는(acting) 방식과 형태를 살펴보는 일에서 시작되어야 합니다.
기본 단위: 행위
이제 OOP 세계에서의 기본 단위로서 행위(action)를 살펴보고자 합니다. 여기에서의 행위는 모듈의 내부 속성이나 행동(behavior)을 의미하는 것이 아닙니다.
저는 행위를 행위자 간 네트워크 내에서 다른 행위자에게 영향을 미치는 것으로 이해하고 싶습니다. OOP에서의 객체는 모두 행위자이며, 행위는 단순히 클래스에 구현된 메서드가 아닙니다. 여기에서 1998년 앨런 케이가 자신이 OOP에서 중요하게 여기는 것은 오직 (1) 메시징(messaging), (2) 상태-프로세스의 지역적 보유(local retention)와 보호 및 은닉(protection and hiding), (3) 그리고 모든 것의 극도로 늦은 바인딩(extreme late-binding)이라고 했던 것의 의미를 다시 생각해볼 수 있습니다.
또한, 비록 앨런 케이가 생물학적 메타포 속에서 객체 지향 프로그래밍을 발전시켜왔지만, 앞으로의 설명에서는 필수적이지 않은 부분을 제외하고는 생물학적 메타포에 기반해 이해하고자 하지 않을 것입니다. 오히려 개인용 컴퓨팅 시스템이라는 측면이 훨씬 중요하다고 여기는 까닭입니다. 특히 메시징을 가장 중요한 개념(big idea)이라고 일컫는 서술은 통합적인 이해를 위해 의도적으로 배제했습니다.
(1) 메시징
메시징은 객체 간의 소통 방식이자 협력의 기반입니다. 특히, 메시징의 가장 중요한 의의는 메시지는 명령이 아니라는 점입니다. 메시지는 행위자가 다른 행위자에게 요청하는 것이지, 명령을 하달하는 일과는 다릅니다.
| 특성 | 메시지 | 명령 |
|---|---|---|
| 소통 방식 | 요청적 | 지시적 |
| 전달 내용 | 의도 (what) | 수행 방법 (how) |
| 처리 결정 | 수신자에게 위임 | 송신자가 통제 |
| 결합도 | 낮음 | 높음 |
| 수신자 역할 | 자율적 | 수동적 |
아래 예시 코드는 각각 메시징과 명령 방식으로 구현된 계좌 출금 코드입니다. 메시징에서는 “계좌에서 출금해 주세요”라는 메시지를 보내고, 명령에서는 “계좌 잔액 변수에서 금액을 빼세요”라는 명령을 내립니다.
// 메시지 전송 - "무엇을" 할지만 요청
public void processWithdrawal(Account account, double amount) {
// 계좌에 출금 "메시지"를 보냄
// "계좌에서 출금해 주세요"
account.withdraw(amount);
}
// Account 클래스 - 자율적인 객체
public class Account {
private double balance;
private TransactionHistory history;
public void withdraw(double amount) {
// 객체가 스스로 결정하고 처리함
if (amount <= 0) {
throw new IllegalArgumentException("출금액은 양수여야 합니다");
}
if (balance < amount) {
throw new InsufficientFundsException("잔액이 부족합니다");
}
// 내부 구현은 객체가 책임짐
balance -= amount;
history.recordWithdrawal(amount);
// 필요한 부수 효과도 객체가 처리
notifyWithdrawal(amount);
}
private void notifyWithdrawal(double amount) {
// 출금 알림 처리
}
}
위의 메시징에서는 계좌 객체가 자율적으로 메시지를 받아들인 다음 결정하고 처리합니다. 내부적으로 잔액을 이용하는지 등의 구현이 숨겨지고, 잔액 역시 어떻게 관리되는지 외부에서 알 수 없게 캡슐화되어 있습니다. 여기에서 객체는 메시지를 능동적으로 수신하고 처리합니다.
// 명령 하달 - "어떻게" 할지 지시
public void processWithdrawal(Account account, double amount) {
// 계좌에 직접적인 "명령"을 내림
// "계좌 잔액 변수에서 금액을 빼세요"
// 비즈니스 로직을 외부에서 처리
if (amount <= 0) {
throw new IllegalArgumentException("출금액은 양수여야 합니다");
}
if (account.getBalance() < amount) {
throw new InsufficientFundsException("잔액이 부족합니다");
}
// 객체의 내부 상태를 직접 조작
account.setBalance(account.getBalance() - amount);
// 부수 효과도 외부에서 처리
recordWithdrawal(account, amount);
sendWithdrawalNotification(account, amount);
}
// Account 클래스 - 수동적인 데이터 구조
public class Account {
private double balance;
// getter와 setter로 내부 상태 노출
public double getBalance() {
return balance;
}
public void setBalance(double balance) {
this.balance = balance;
}
}
// 외부에서 처리하는 부수 효과들 - 중앙에서 하달
private void recordWithdrawal(Account account, double amount) {
// 출금 기록 처리
}
private void sendWithdrawalNotification(Account account, double amount) {
// 출금 알림 처리
}
명령에서는 계좌 객체가 수동적으로 명령을 받아들이고, 이를 외부에서 처리합니다. 비즈니스 로직은 외부에서 처리되고, 잔액 변수는 직접 조작됩니다. 즉, 외부에서 이미 계좌가 어떻게 내부적으로 잔액을 이용하고 관리하는지도 알게 됩니다.
두 코드를 비교하면 메시징에서는 제어 흐름이 객체 내부로 들어가지 않고, 명령에서는 제어 흐름이 객체 내부로 들어가는 것을 확인할 수 있습니다.
특히, 부수 효과의 경우에 메시징은 객체 내부에서 처리하는 반면 명령에서는 외부에서 중앙 하달식으로 처리되어야 할 것입니다. 비록 예시 코드에서는 작성되지 않았지만, 메시징의 이러한 제어 흐름은 추상화된 인터페이스를 통해 의존성 역전을 가능하도록 만든다는 중요성도 있습니다.
(2) 상태-프로세스의 지역적 보유, 보호 및 은닉
앨런 케이의 용어를 그대로 가져온 것은 캡슐화의 더욱 근본적인 측면을 강조하고 싶기 때문입니다. 이는 캡슐화라는 단어 자체에서 보호와 은닉에만 집중하면 객체가 데이터와 메서드가 합쳐진 무언가라고 여겨지는 오해를 불러 일으킨다고 생각하기 때문인데요. 특히, 캡슐화는 정보 은닉과 접근 제어와 같은 기술적 구현의 일종이라고 보는 것이 더 적절한데도 말입니다.
반면, 상태-프로세스의 지역적 유지는 더욱 근본적으로 객체의 책임과 자율성을 논하는 용어입니다. 여기에서 중요한 것은 객체 내부에서 독립적으로 책임지는 상태와 프로세스가 통합된다는 점입니다. 절차적 프로그래밍에서는 데이터와 프로시저가 분리되어 있었다는 점을 생각해보면 이해가 쉽습니다.
// 데이터 구조체 정의
struct Account {
double balance;
char owner[100];
// ...
};
// 분리된 프로시저
void withdraw(struct Account* account, double amount) {
if (amount > 0 && account->balance >= amount) {
account->balance -= amount;
}
}
위 C코드에서는 데이터 구조체는 수동적인 정보의 컨테이너로 남고, 프로시저는 그러한 데이터를 들여다보고 외부에서 조작합니다. 데이터와 프로시저 사이에는 따라서 본질적인 연결이 없습니다. 데이터 구조체와 프로시저의 흐름이 분리되어 있다고 보면 쉽습니다. 절차형 프로그래밍에서 데이터 구조체는 데이터 구조체 자체로 존재하고, 프로시저는 프로시저 자체로만 존재합니다. 프로시저의 흐름이 데이터 구조체의 흐름에 간섭할 뿐입니다.
반면, 앨런 케이의 “상태-프로세스(state-process)”라는 말은 상태와 프로세스가 가지는 흐름이 객체 내에서 모두 통합됨을 의미합니다. 여기에서 앨런 케이가 “데이터를 없애고 싶었다(I wanted to get rid of data)”고 한 말은 풀어서 이해하자면 (흐름이 동떨어져 존재하는) 데이터를 없애고 싶었다는 뜻으로도 읽힙니다.
class Account {
// 상태: 잔액과 계좌 등급
private double balance;
private AccountStatus status; // REGULAR, PREMIUM, FROZEN
// 행위: 출금이라는 맥락
public boolean withdraw(double amount) {
// 상태(status)가 행위의 실행 방식을 결정
if (status == AccountStatus.FROZEN) {
return false; // 동결된 계좌는 출금 불가
}
// 상태(balance)가 행위의 실행 방식을 결정
if (balance < amount) {
return false; // 잔액 부족
}
// 행위의 결과로 상태(balance)가 변경됨
balance -= amount;
// 상태(status)에 따라 추가 행위가 달라짐
if (status == AccountStatus.PREMIUM) {
addRewardPoints(amount * 0.01); // 프리미엄 계좌는 리워드 포인트 적립
}
// 행위의 결과로 상태 전이가 발생할 수 있음
if (status == AccountStatus.PREMIUM && balance < 10000) {
status = AccountStatus.REGULAR; // 잔액이 기준 미달시 일반 계좌로 강등
}
return true;
}
private void addRewardPoints(double points) { /* ... */ }
}
위 코드와 주석에서 볼 수 있듯, 데이터 자체는 독립적인 개체가 아니라 객체 내부의 프로세스 흐름 속에서 의미를 지니게 됩니다. 따라서 제가 보기에는 앨런 케이가 의도적으로 데이터라는 용어 대신, 생물학적 메타포에서 영감을 받아 ‘상태’라는 말로 이를 표현했다고 생각합니다. 특히 객체에서는 더 이상 데이터나 프로시저 자체가 중요한 것이 아니라 객체의 행위를 구성하는 상태-프로세스의 흐름이 더 중요해지기 때문이기도 하겠습니다.
그렇다면 “지역적 보유(local retention)”라는 말은 객체 내부에서 상태-프로세스의 흐름이 외부의 상태-프로세스 흐름과 교차되어서는 안됨을 의미합니다. 이는 경계에 대한 이야기이자, 객체 자신이 상태-프로세스에 대해 자율적인 책임을 지고 있다는 뜻이기도 합니다. 자율이라는 뜻이 스스로 규율을 정하고 지킨다는 뜻임을 떠올리면 쉽습니다.
예시 코드에서는 addRewardPoints 메서드가 외부에서 호출되지 않고, 객체 내부에서 자율적으로 호출되는 것을 확인할 수 있습니다. 이는 객체 자신이 상태-프로세스에 대해 자율적인 책임을 지고 있다는 뜻이기도 합니다.
따라서 보호 및 은닉이 중요해지는 것이고, 자연스럽게 메시징은 객체 간 통신에서 중요한 역할을 차지합니다. 한 객체가 다른 객체에게 규율을 강요하거나 외부에서 흐름을 조작하면 더 이상 자율적일 수 없으니까요. 캡슐화 시 결합도가 낮아지고 유지보수성이 높아지는 이유도 자율성 측면에서 이와 같기 때문입니다.
(3) 모든 것의 극도로 늦은 바인딩
극도로 늦은 바인딩(extreme late-binding)은 객체가 메시지를 받았을 때 어떻게 응답할지를 런타임에 스스로 결정하게 만든다는 점에서 중요합니다. 즉, 송신자는 수신자가 메시지를 어떻게 처리할 지 알 필요가 없습니다. 타입이든 메서드든 모두 런타임에 결정되고, 그 결정권은 수신자에게 있습니다. 따라서 느슨한 결합이 일어나고, 늦은 바인딩이 다형성이라는 특성으로도 이어지는 것입니다.
여기에서 “극도로(extreme)”라는 말은 메서드 디스패치만이 아니라 타입, 객체 관계, 언어 구조 등 모든 측면이 런타임에 결정된다는 뜻입니다. 이는 Java 코드로는 예시를 들기가 쉽지 않습니다.
대신 앨런 케이가 개발한 Smalltalk에서는 doesNotUnderstand: 메커니즘을 통해 예상치 못한 메시지에 대응할 수 있습니다.
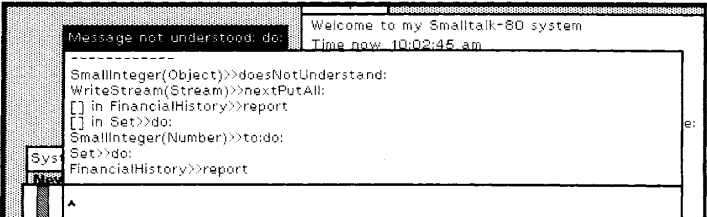
출처: “Smalltalk-80: The Language and its Implementation”
위 이미지는 Smalltalk-80 시스템에서 객체가 이해할 수 없는 메시지를 받았을 때 발생하는 오류를 보여줍니다.
SmallInteger(Object)>>doesNotUnderstand: #nextPutAll은 정수 객체가 이해할 수 없는 nextPutAll: 메시지를 받아 doesNotUnderstand: 메서드가 호출되었음을 나타냅니다.
이 메커니즘은 메시지에 맞는 메소드가 없다면 기본적으로 이에 대해 Smalltalk 디버거를 호출하나, 오버라이드하는 방식으로 런타임에 구현되지 않은 메시지를 가로챌 수 있습니다.
곧, 극도로 늦은 바인딩은 프로그래밍 언어를 넘어 시스템적 차원에서의 런타임 안정성으로 향한다고도 볼 수 있습니다. 시스템의 한 부분에 문제가 생겨도 부분적인 실패를 허용하고 런타임에도 새로운 기능을 추가하거나 버그를 수정할 수 있으니까요. 또한, 한 부분이 변경되었다고 해서 다시 시스템을 컴파일하고 시작할 필요도 없다는 점에서 안정성이 보장됩니다. 이는 앞서 말씀드렸듯, 앨런 케이가 최소한의 컴퓨팅 단위로 객체를 정의하고자 한 것과 일맥상통합니다.
진짜 OOP 세계?
그렇다면 지금까지 살펴보았듯이, 앨런 케이가 1998년에 정의내린 OOP가 “진짜 OOP”일까요? 이를 이해하는 것이 정말로 OOP를 이해하는 유일한 방식일까요? 그렇다면 현대의 C++, Java 등의 언어도 OOP와 동떨어져 있을까요? 저는 그렇지 않다고 대답하고 싶습니다. 그러나 앨런 케이의 OOP가 완전히 잘못되었다고 말하고 싶지도 않습니다. 첫번째는 역사적인 관점에서 그러하고, 두번째는 실용적인 관점에서 그러합니다.
역사적 관점: 객체 지향의 뿌리
(1) Smalltalk: 메시지 중심 객체지향
앨런 케이가 말하는 OOP가 시스템적 측면을 강조하고 있음은 우연이 아닙니다. Smalltalk 혹은 앨런 케이의 OOP를 저는 현대 OOP의 메시지 중심 객체지향의 뿌리라고 일컫고 싶습니다.
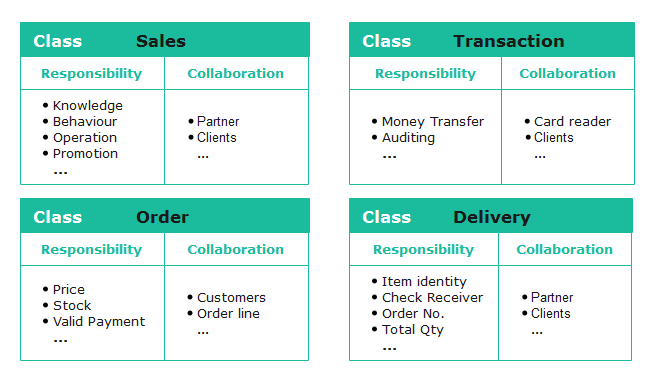
특히 Smalltalk 커뮤니티의 켄트 백(Kent Beck)과 워드 커닝햄(Ward Cunningham)이 CRC(Class-Responsibility-Collaboration) 기법을 통해 객체의 자율성과 책임에 기반한 객체 간의 협력 네트워크를 형성하는 일을 제시한 것은 우연이 아니라고 생각합니다.
또한, 설계적 측면에서 시스템 행위를 동적으로 수정하고 이벤트 기반의 아키텍처를 형성할 수 있는 기반을 닦아놓은 것 역시 Smalltalk이 미친 영향이라고 생각합니다.
(2) Simula: 모델링 중심 객체지향
그렇다면 Simula는 모델링 중심 객체 지향의 뿌리라고 부르고 싶습니다. Simula는 실세계를 소프트웨어로 모델링하는 구조적 메커니즘에 초점을 맞추는 언어입니다.
따라서 복잡한 시스템을 모델링하기 위해 클래스와 객체라는 개념을 도입했으며, 이 개념은 현대 객체지향 언어의 기본 구조가 되었습니다. Smalltalk 역시 객체 개념을 Simula에서 영향 받았음을 밝힌 적 있습니다.
CLASS Shape;
BEGIN
REAL x, y;
! 가상 프로시저 선언 ;
VIRTUAL: PROCEDURE draw;
! 가상 프로시저 기본 구현 ;
PROCEDURE draw;
BEGIN
OutText("기본 도형 그리기");
END;
END;
Simula는 클래스와 클래스의 객체라는 용어를 도입했고, 클래스 접두어(class prefixing)을 통한 상속 구현은 현대 객체 지향 프로그래밍 언어에서도 여전히 살펴볼 수 있습니다. 또한, Simula의 가상 프로시저(virtual procedure)는 현대 객체 지향 프로그래밍에서 오버라이드(override)와 같은 개념으로 이어졌습니다.
위 코드에서 Shape CLASS Circle과 같이 클래스 접두어를 이용해 상속을 진행할 수 있고, 해당 Circle 클래스 내에서 PROCEDURE draw를 정의함으로써 오버라이드가 가능합니다. 또한, 객체를 생성하고 참조가 Circle 객체를 가리키도록 함으로써 다형성도 지원이 됩니다.
모델링 중심 객체지향은 시스템을 설계하고 구조화하는 데 강력한 도구를 제공했습니다. Simula의 접근 방식은 특히 도메인 모델링과 분석 단계에서 실세계 개념을 소프트웨어 구조로 매핑하는 데 도움이 되었고, UML(Unified Modeling Language)과 같은 객체지향 모델링 언어에도 영향을 미쳤습니다. 실제로 UML의 창시자 중 한 명인 Grady Booch는 Simula의 모델링 능력에서 영감을 받았다고 여러 차례 언급했습니다.
(3) 두 뿌리의 융합과 발전
현대 객체지향 프로그래밍은 Smalltalk의 메시지 중심 접근법과 Simula의 모델링 중심 접근법이 다양한 방식으로 융합되고 발전한 결과물입니다. 이 두 가지 접근법은 상호보완적이며, 각각 객체지향 패러다임의 다양한 측면을 강조합니다. 메시지 중심 접근법은 시스템의 행위적 측면을, 모델링 중심 접근법은 시스템의 구조적 측면을 포착합니다.
Java와 C#과 같은 주류 객체지향 언어들은 Simula의 클래스 기반 구조와 정적 타입 시스템을 채택하면서도, 인터페이스와 다형성을 통해 Smalltalk의 메시지 전송 모델의 일부 측면을 통합했습니다. 반면 Ruby와 Python 같은 동적 언어들은 Smalltalk의 유연한 메시지 전송 모델에 더 가까우면서도, 클래스와 상속이라는 Simula의 구조적 개념을 채택했습니다.
객체지향 설계 방법론 역시 이 두 가지 뿌리의 영향을 받았습니다. 도메인 주도 설계(Domain-Driven Design)는 Simula의 모델링 중심 접근법에서 영감을 받아 비즈니스 도메인을 소프트웨어 모델로 표현하는 데 초점을 맞춥니다. 또한, 책임 주도 설계(Responsibility-Driven Design)는 Smalltalk의 메시지 중심 접근법에서 영향을 받아 객체의 책임과 협력에 초점을 맞춥니다. 물론, 두 방법론이 다른 접근법을 배제했다는 뜻을 읽히지는 않았으면 좋겠습니다. 이는 이후 실용적 관점에서 밝히겠습니다.
실용적 관점: 객체 경계의 융합
실용적 관점에서 OOP를 바라볼 때 가장 중요한 것은 “어떤 OOP가 진짜인가”라는 본질이나 순수성에 관한 질문이 아니라, 그러한 “OOP가 어떻게 이용되며 실현되어왔는가”를 살펴보는 일입니다. 저는 OOP가 실현되고 이용되는 과정에서 문제 의식의 경계가 설정되고, 이러한 경계 설정이 곧 객체가 가지는 개념적 경계와 융합되어왔음을 주장하고자 합니다.
특히, 객체(object)의 개념이 시간이 지나면서 다른 경계와 융합되어 왔고, 지금 우리가 다루는 시스템에서는 그 범위가 급격히 넓어진 것이 이를 뒷받침합니다. 이러한 확장은 단순한 코드에서의 변화라기보다는 시스템이나 설계를 바라보는 관점 변화로도 나아감을 의미합니다.
(1) 전통적인 객체: 프로그램 메모리 경계
Simula, Smalltalk 등 초기 객체지향 언어에서 객체는 프로그램 안의 구조화된 단위로서 큰 의미를 차지했습니다. 이 시기에 객체는 애플리케이션 내부에서, 주로 메모리 내에 존재하는 클래스의 인스턴스를 의미했습니다. 즉, 객체라는 단어가 가지는 경계 범위는 실행중인 프로그램에 국한됩니다.
Simula에서는 객체가 프로세스(process)라고 불리며, 메모리 내에서 실행되는 시뮬레이션 엔티티를 의미했습니다. 여기에서 객체는 데이터와 프로시저를 결합한 단위이자, 명확히 메모리에 할당되는 런타임 구조(runtime structure)로 이해되었습니다.
Smalltalk-80에서는 객체가 “객체 테이블”이라는 메모리 구조에 저장되었으며, 각 객체는 객체지향 포인터(Object-Oriented Pointer)를 통해서 메모리에 올라간 객체 테이블의 인덱스가 됩니다. 여기에서 객체 테이블은 실제 객체 데이터의 메모리 위치를 추적하는 계층으로, 간접적인 참조를 가능케 합니다.
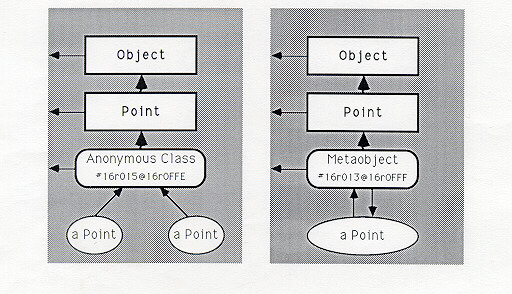
위 그림에서 보이는 16진수 값(#16r0150160FFE, #16r0130160FFE)이 객체 테이블의 인덱스인 객체 지향 포인터입니다. 여기에서 메타오브젝트(Metaobject)에도 객체 지향 포인터가 존재한다는 것은 Smalltalk의 철학인 “모든 것은 객체다”를 뒷받침하듯, 클래스 또한 메모리에 올라간 인스턴스 객체임을 보여줍니다.
객체 지향의 메시지적 측면과 모델링적 측면을 드러내는 두 언어에서, 현재에도 굳건히 이어져오는 객체와 인스턴스의 관계를 찾아볼 수 있습니다. 그런데 이러한 객체 개념은 더 이상 프로그램 메모리만을 경계로 삼지 않는데요.
(2) 진화하는 객체: 융합되는 경계
객체가 가지는 의미는 이제 더 이상 프로그램 메모리만을 경계로 삼지 않습니다. 객체 개념은 다양한 영역과 융합되며 그 경계를 확장해왔습니다. 대표적인 예시로 마이크로서비스(Microservice), 도메인 주도 설계(DDD, Domain-Driven Design), 쿠버네티스(k8s, kubernetes)를 살펴볼 수 있습니다. 이 모두에서 앞서 살펴본 역사적 관점에서의 모델링 중심 객체지향과 메시지 중심 객체지향의 면모가 엿보이기도 합니다.
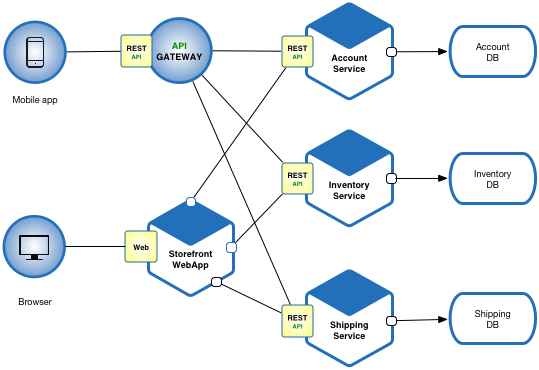
(출처: microservices.io - patterns/microservices)
마이크로서비스는 객체지향 원칙을 어플리케이션 시스템 경계에서 재해석한 사례입니다. 여기에서 객체의 캡슐화, 단일 책임 원칙(SRP), 메시지 기반 통신과 같은 객체지향 원칙은 프로그램 메모리 경계를 넘어 어플리케이션 시스템 수준으로 확장되었습니다. 위 그림에서도 드러나듯, 마이크로서비스는 비즈니스 능력을 중심으로 서비스를 분리함으로써 단일 책임 원칙을 시스템 수준에서 구현합니다. 또한, 각 서비스는 자신의 데이터를 캡슐화하고 API를 통해서만 상호작용합니다.
도메인 주도 설계는 객체 개념이 비즈니스 도메인 경계와 융합된 대표적 사례입니다. DDD에서는 객체가 비즈니스 도메인의 개념적 경계와 일치하도록 재정의됩니다. 바운디드 컨텍스트라는 개념을 통해 객체의 의미와 책임이 비즈니스 맥락 내에서 명확하게 정의되고, 컨텍스트 간 경계가 관리됩니다.
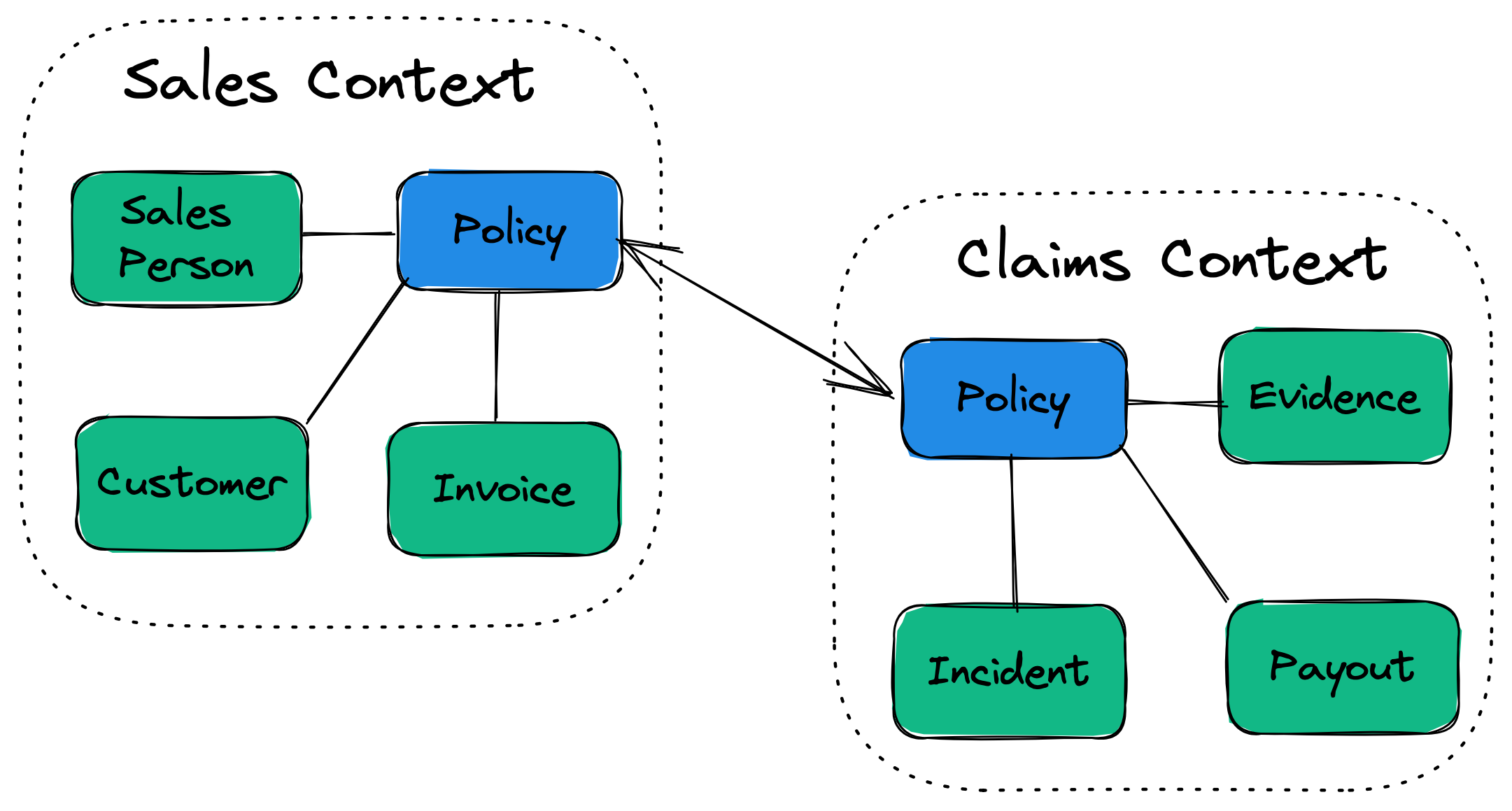
(출처: antman-does-software.com)
위 그림에서도 드러나듯, 컨텍스트 맵에서 Sales Context나 Claims Context 같은 바운디드 컨텍스트는 객체 개념이 비즈니스 도메인의 개념적 경계와 일치하도록 재정의됩니다.
또한, 유비쿼터스 언어는 코드 상의 객체와 비즈니스 언어 사이의 구분이 허물어지는 계기로서 작용합니다.애그리게이트 루트를 통한 경계 설정은 객체 간의 관계와 트랜잭션 경계를 비즈니스 규칙에 맞게 재구성하구요. 즉, 객체 개념은 단순한 기술적 구성체를 넘어 비즈니스 도메인의 개념적 경계와 융합됩니다.
쿠버네티스에서는 객체 개념이 인프라스트럭처 경계와 융합되었습니다. 쿠버네티스에서 파드(Pod)는 객체지향 프로그래밍의 객체와 유사한 방식으로 존재합니다. 특히 파드가 “생성하고 관리할 수 있는 배포 가능한 가장 작은 컴퓨팅 단위”라는 공식 문서의 설명은 앨런 케이의 OOP를 떠올리게 하는데요. 각 파드는 고유한 식별자와 상태를 가지며, 다른 파드와 네트워크를 통해 메시지를 주고 받습니다.
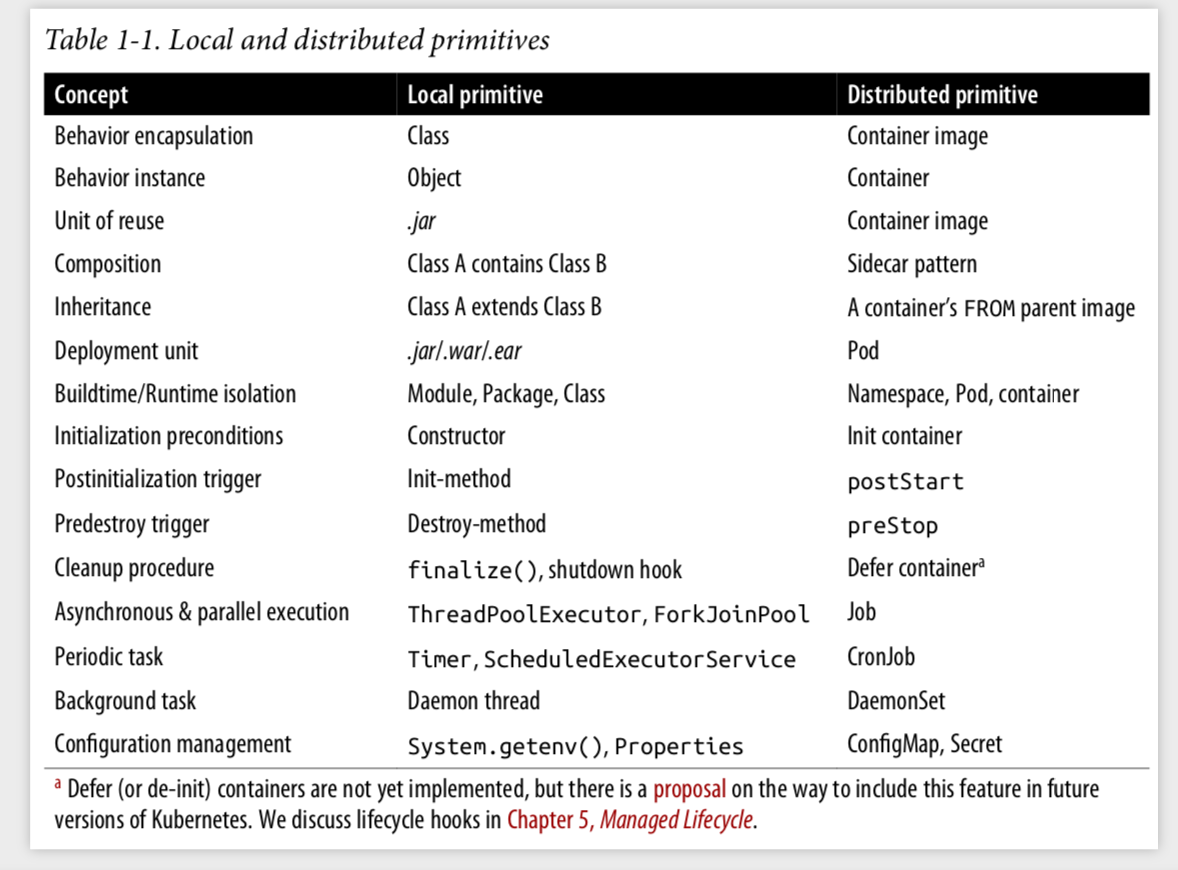
위 자료에서 볼 수 있듯이, 객체지향 프로그래밍의 여러 개념들은 쿠버네티스의 개념들과 직접적으로 매핑되기도 합니다. 이처럼 쿠버네티스는 객체지향 패러다임을 인프라 수준으로 확장하여, 분산된 인프라스트럭처를 객체들의 네트워크로 모델링했습니다.
이러한 융합을 통해 객체 개념은 클래스-인스턴스 관계를 넘어서 어플리케이션 시스템 설계와 소프트웨어 설계 방법론, 그리고 인프라스트럭쳐 경계와도 융합했습니다. 이는 객체가 가지는 경계가 코드와 메모리 경계 수준을 넘어 더 넓은 영역으로 확장되었음을 보여줍니다. 그리고 이러한 경계의 확장은 동시에 객체지향 패러다임의 범위가 넓어지는 것이기도 합니다.
나가며
OOP를 바라보는 시선을 재고하며, 객체의 의미와 그 확장된 경계를 탐구해보았습니다. 앨런 케이가 말한 OOP의 핵심 요소인 메시징, 상태-프로세스의 지역적 보유와 보호 및 은닉, 그리고 모든 것의 극도로 늦은 바인딩을 중심으로 객체를 행위자로서 이해하는 관점을 살펴보았습니다.
그리고 꼭 앨런 케이의 OOP에 기반한 OOP만이 추구해야할 것은 아님 역시 살펴보았습니다. 객체 지향 프로그래밍은 크게 두 가지 뿌리에서 발전해왔는데요. 특히, Smalltalk의 메시지 중심 객체지향과 Simula의 모델링 중심 객체지향을 중심으로 살펴보았습니다.
현대의 객체 지향 언어와 방법론은 이 두 가지 뿌리의 융합과 발전의 결과물입니다. 따라서 저는 어느 한 쪽만이 “진정한 OOP”라고 주장하기보다는, 각각의 관점이 객체지향 패러다임의 다양한 측면을 조명하고 이를 확장해왔다고 보는 것이 적절하다고 말씀드리고 싶습니다.
나아가 객체 지향의 진정한 가치는 코드의 구조적 아름다움이나 이론적 순수성이 아니라, 복잡한 시스템을 이해하고 관리하기 쉬운 방식으로 설계하는 능력에 있다고 생각합니다.
그러나 OOP가 모든 문제를 완벽하게 해결하는 것은 아닙니다. 일례로 관점 지향 프로그래밍(Aspect-Oriented Programming, AOP)은 절차 지향 프로그래밍과 객체 지향 프로그래밍 모두에 존재하는 문제를 해결하기 위해 등장했습니다.
다음 글에서는 이러한 OOP 세계에서 AOP가 가지는 의미와 역할, 그리고 Spring 프레임워크에서 AOP가 어떻게 구현되고 활용되는지 살펴보겠습니다.
Reference
Goldberg, A., & Robson, D. (1983). Smalltalk-80: The Language and its Implementation. Retrieved from http://stephane.ducasse.free.fr/FreeBooks/BlueBook/Bluebook.pdf
Foote, B., & Johnson, R. E. (1989). Reflective facilities in Smalltalk-80. ACM SIGPLAN Notices, 24(10), 327-335. Retrieved from https://doi.org/10.1145/74878.74911
Kay, A. C. (1993). The Early History of Smalltalk. ACM SIGPLAN Notices, 28(3), 69-95. Retrieved from http://worrydream.com/EarlyHistoryOfSmalltalk/
Kay, A. C. (1998). Dr. Alan Kay on the Meaning of “Object-Oriented Programming” [Email interview]. Retrieved from http://userpage.fu-berlin.de/~ram/pub/pub_jf47ht81Ht/doc_kay_oop_en
Dahl, O. J., & Nygaard, K. (1966). SIMULA: an ALGOL-based simulation language. Communications of the ACM, 9(9), 671-678. Retrieved from https://doi.org/10.1145/365813.365819
INTRODUCTION TO OOP IN SIMULA http://staff.um.edu.mt/jskl1/talk.html
A Conversation with Alan Kay https://queue.acm.org/detail.cfm?id=1039523
understanding-kubernetes-from-the-perspective-of-application-development https://www.alibabacloud.com/blog/understanding-kubernetes-from-the-perspective-of-application-development_597457
Beck, K., & Cunningham, W. (1989). A laboratory for teaching object-oriented thinking. ACM SIGPLAN Notices, 24(10), 1-6. Retrieved from https://doi.org/10.1145/74877.74879
Brandolini, A. (2009). Strategic Domain Driven Design with Context Mapping. Retrieved from https://www.infoq.com/articles/ddd-contextmapping/
쿠버네티스 공식문서 - 파드 https://kubernetes.io/ko/docs/concepts/workloads/pods/
Richardson, C. (n.d.). Pattern: Microservice Architecture. Retrieved from https://microservices.io/patterns/microservices.html